ACM KDD 2014 in New York City

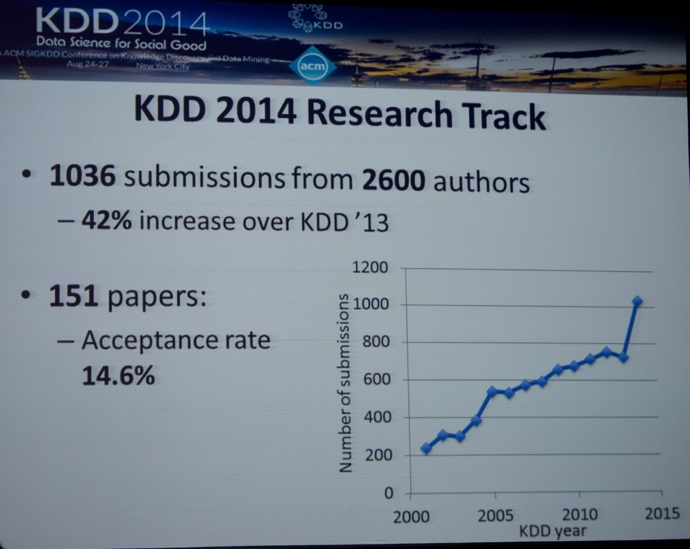
This year, a record-breaking number of attendees (KDD: 2,060 + 260 Bloomberg only = 2,320 in total) came to New York City, NY for the KDD 2014 conference - the premier international data mining conference (#KDD2014). The record attendance was mostly explained by a huge participation from industry (over 50% of attendees). The conference theme was “Data Science for Social Good”. The main themes this year included: Deep Learning, Social Network Analysis, Big Data Algorithms, active learning, text mining, HR (or workforce) analytics. Again, I particularly liked the large number of great tutorials. You can download the slides of these tutorials from this page. I also like the fact that more source code is made available to implement the new algorithms being proposed.
This event is organized by ACMs SIGKDD (Knowledge Discovery and Data Mining). In the picture above, you see some of the key organizers of this and previous KDD events.
This is a personal summary of the event, based on my choices of the sessions. All pictures are my own (@dirkvandenpoel). At any time, there were many sessions in parallel, so this summary can only give a partial report of this large event. Let's have an in-depth look at the event in chronological order.
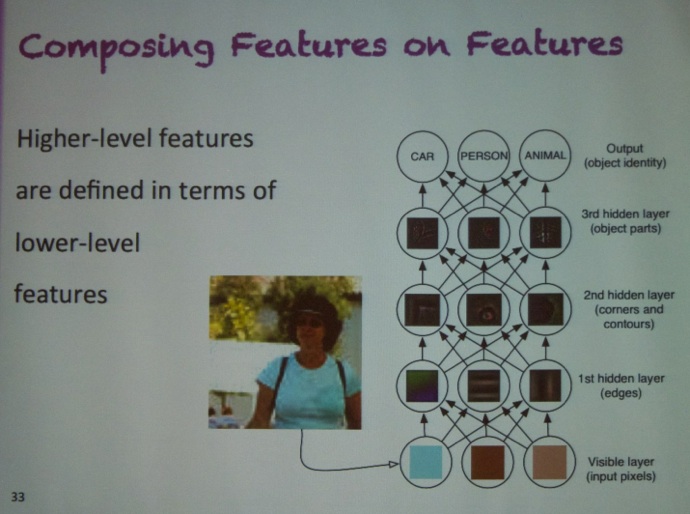
Given the hype about the topic, I decided to attend the Deep Learning tutorial. It has received a lot of interest in the machine learning community because of its strong industrial impact, in particular for high-dimensional perceptual data such as speech and images, but also in NLP (natural language processing). The morning session was taught by Russ Salakhutdivov (University of Toronto, see picture below). He discussed the sparse coders, how an autoencoder works, the concept of stacked autoencoders, Deep Belief Networks (DBNs). Lots of the magic lies in the training of these networks.
Wednesday 27 August 2014

Congratulations to the organizing committee for bringing together a great group of academics and company data scientists in beautiful New York City!



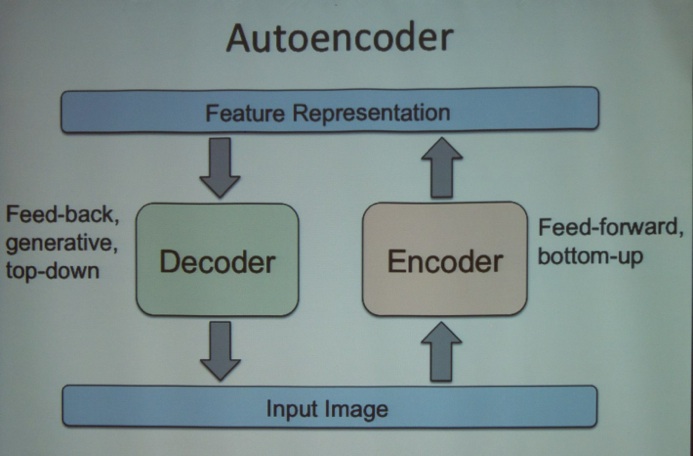



In the afternoon, Prof. Dr. Yoshua Bengio (Université de Montréal, see picture below) continued the “Deep Learning” theme with his tutorial “Scaling up Deep Learning”. He started off by explaining that Deep learning is based on the idea of learning multiple levels of representation, with higher levels computed as a function of lower levels, and corresponding to more abstract concepts automatically discovered by the learner. He also emphasized the need for GPUs to speed up processing.





Next up was the opening ceremony. Michael Zeller (@MichaelZeller, CEO of @Zementis and 2014 member of the executive committee at SIGKDD, see picture below) had the honor of opening the event.


Next, a long list of awards was presented to the winners. I show a few random pictures of that part below. Click here for more details. The organizers should cut down on the time allotted to this part of the program. The added value to the audience was minimal. Congratulations to all of the awardees.
Next, the conference co-chairs: Dr. Claudia Perlich (@Claudia_Perlich, Dstillery, see picture below) and Dr. Sofus Macskassy (Facebook, see picture below) took the stage. The hottest research topics (operationalized as the highest acceptance rate) for this conference edition included: Big Data, supervised learning, unsupervised learning, recommender systems, ... .






Next, Ted Senator (see picture below, to the right) was awarded the 2014 SIGKDD Service Award.

Finally, this year’s Innovation Award Winner is: Prof. Dr. Pedro Domingos (University of Washington, see picture below).

Prof. Dr. Pedro Domingos (University of Washington) then went on to hold his very interesting Innovation Award talk titled “Principles of Very Large-Scale Modeling”. He also mentioned his forthcoming book “The Master Algorithm: Machine Learning and the Big Data Revolution”.




Monday, August 25th, started off with a complementary breakfast, followed by the paper spotlight session (a limited-time one-slide summary of every paper by one of the authors). Below, you see pictures of random “spotlight” presenters.


Next, Dr. Oren Etzioni (@Etzioni, CEO at Allen Institute for AI) gave the morning keynote “The Battle for the Future of Data Mining”. His new institute aims to take up some “grand” challenges. Their first goal, however, is to develop an open question answering system, which will be able to answer questions from 4th grade science exams.




After the keynote, attendees were given the opportunity to ask questions.

Next, the coffee break also marked the start of the exhibit floor. It was clear the many well-known companies are hiring data scientists...


Next, I decided to attend the “Commercial & Industry Applications” Session. It started off with a talk by Sri Subramaniam (Groupon, see picture below) titled “Frontiers in e-commerce personalization”. He highlighted the importance of product-category hierarchies at the #KDD2014 conference, but users also like serendipity. His most remarkable quote: "It's a thin line between creepiness and delight: transparency and explanations push the frontier".
Next up was the combined presentation by Tracey De Poalo (Sprint, see picture below) and Jeremy Howard (@jeremyhoward, Enlitic, see picture below) titled “Predictive Modeling in Practice — How to build a $1B model in 20 days”.









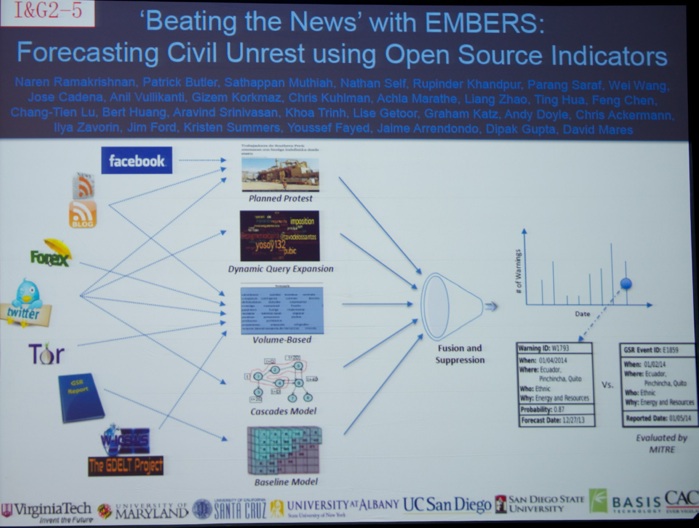
After lunch, I first attended the Supervised Learning Session. This session started with the talk titled “A Multi-class Boosting Method with Direct Optimization” by Shaodan Zhai (Wright State University), Tian Xia (Wright State University), Shaojun Wang (Wright State University).





Next, I attended the presentation titled “FastXML: A Fast, Accurate and Stable Tree-classifier for eXtreme Multi-label Learning” by Yashoteja Prabhu (Indian Institute of Technology - Delhi), Manik Varma (Microsoft Research).




Afterwards, I decided to walk the exhibit floor. A large number of big companies was hiring data scientists. Even Apple had a booth! Siemens was one of the few companies distributing a lot of goodies...







After the coffee break, I attended the Fraud/Threat Detection Session. The first talk was titled “Guilt by Association: Large Scale Malware Detection by Mining File-relation Graphs” by Acar Tamersoy (Georgia Institute of Technology), Kevin Roundy (Symantec Research Labs), Duen Horng Chau (Georgia Institute of Technology).


The next talk was titled “Knock It Off: Profiling the Online Storefronts of Counterfeit Merchandise” by
Matthew F Der (University of California, San Diego), Lawrence K Saul (University of California, San Diego), Stefan Savage (University of California, San Diego), Geoffrey M Voelker (University of California, San Diego).



The next talk was titled “Corporate Residence Fraud Detection” by Enric Junqué de Fortuny (University of Antwerp), Marija Stankova (University of Antwerp), Julie Moeyersoms (University of Antwerp), Bart Minnaert (Ghent University), Foster Provost (New York University), David Martens (University of Antwerp).

“Improving Management of Aquatic Invasions by Integrating Shipping Network, Ecological, and Environmental Data: Data Mining for Social Good” was presented by Jian Xu (University of Notre Dame), Thanuka L. Wickramarathne (University of Notre Dame), Nitesh V Chawla (University of Notre Dame), Erin K Grey (University of Notre Dame), Karsten Steinhaeuser (University of Minnesota), Reuben P. Keller (Loyola University Chicago), John M. Drake (University of Georgia), David M. Lodge (University of Notre Dame).


Finally, the last talk in this session was titled “Novel Geospatial Interpolation Analytics for General Meteorological Measurements” by Bingsheng Wang (Virginia Tech), Jinjun Xiong (IBM Thomas J. Watson Research Center).



To bridge the gap with the evening event - the poster reception - I walked the exhibit floor. Here are some pictures of the SAS and Bloomberg booth at that time.


Finally, the poster reception offered attendees the opportunity to have in-depth interactions with the authors.



Day 3 - August 26th, 2014 - again kicked off with a paper spotlight session (a.k.a. KDD Madness) of all sessions for that day. See some pictures below...


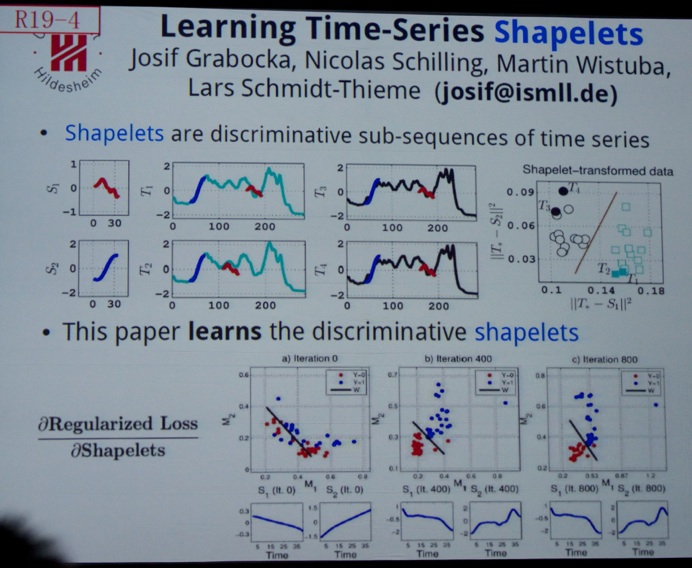

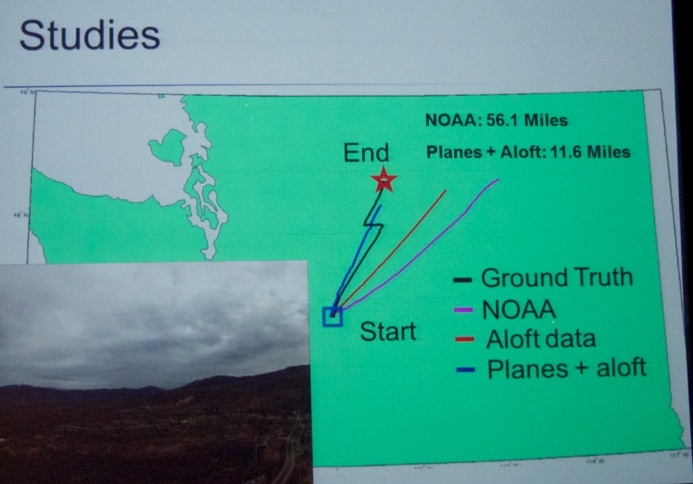
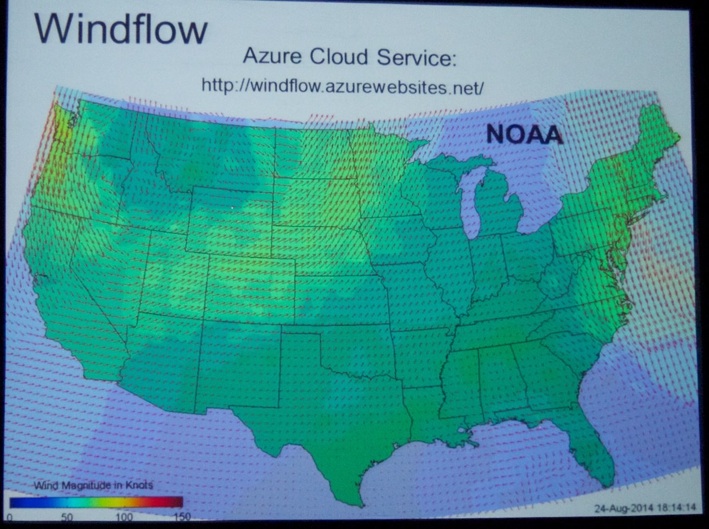
Then, time had come for the opening keynote of Day 3. Dr. Eric Horvitz (@MSFTResearch and @erichorvitz, Director of Microsoft Research, see picture below) gave a talk titled “Data, Predictions, and Decisions in Support of People and Society”. In line with the overall theme of the event - Data Science for Social Good - Dr. Eric Horvitz discussed nice examples of traffic predictions, wind-monitoring systems and predicting hospital readmissions (at discharge of patients, doctors get a list of possible reasons for readmission, see picture below) in the context of developing an informational pipeline that uses data to make a prediction that leads to a decision. He also talked about the value of work to minimize errors in health care. As an #avgeek, yours truly (@dirkvandenpoel) particularly liked his avaition example for predicting wind at higher altitudes based on route-deviation data of selected aircraft. He also mentioned the AI-D (Artificial Intelligence for Development) project.


Next, I attended the Active Learning Session. The interest in this topic was overwhelming. The room was packed... Active learning is a special case of semi-supervised machine learning in which a learning algorithm is able to interactively query the user (or some other information source) to obtain the desired outputs at new data points. The first talk was by Dan Kushnir (Alcatel-Lucent, see picture below) titled “Active-Transductive Learning with Label-Adapted Kernels”.


The second talk was titled “Active Learning For Sparse Bayesian Multilabel Classification” by Deepak Vasisht (MIT), Andreas Damianou (University of Sheffield, UK), Manik Varma (Microsoft Research), Ashish Kapoor (Microsoft Research).



The next talk was titled “Large-Scale Adaptive Semi-Supervised Learning via Unified Inductive and Transductive Model” by De Wang (University of Texas at Arlington), Feiping Nie (University of Texas at Arlington), Hseng Huang (University of Texas at Arlington).

Next, the talk titled “Active Semi-Supervised Learning Using Sampling Theory for Graph Signals” was presented by Akshay Gadde (University of Southern California), Aamir Anis (University of Southern California), Antonio Ortega (University of Southern Calfornia).



The last talk of this session was titled “Active Collaborative Permutation Learning” by Jialei Wang (University of Chicago), Nathan Srebro (Toyota Technological Institute at Chicago), James Evans (University of Chicago).

Next up was the ACM SIGKDD Business Meeting lunch.

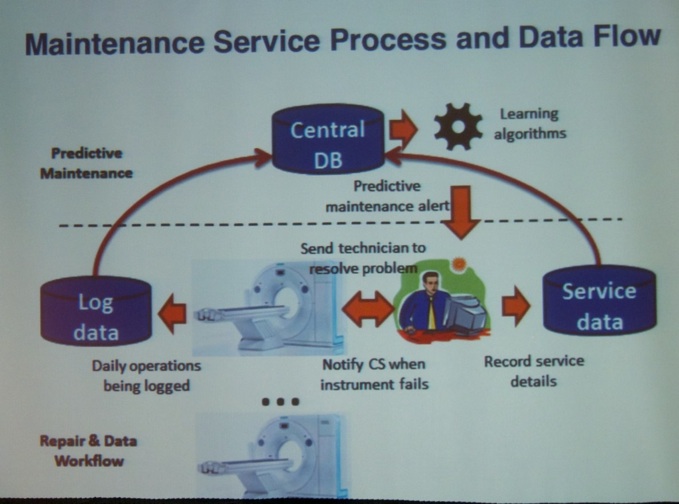
After lunch, I attended the Monitoring & Maintenance Session. The first talk was titled “Log-based Predictive Maintenance” by Ruben Sipos (Cornell University), Dmitriy Fradkin (Siemens Corporation), Fabian Moerchen (Amazon), Zhuang Wang (@SkytreeHQ, Skytree, see picture below). Preventive maintenance offers some serious cost-saving potential.

The next talk was titled “Applying Data Mining Techniques to Address Critical Process Optimization Needs in Advanced Manufacturing” by Li Zheng (Florida International University), Chunqiu Zeng (Florida International University, see picture below) et al.
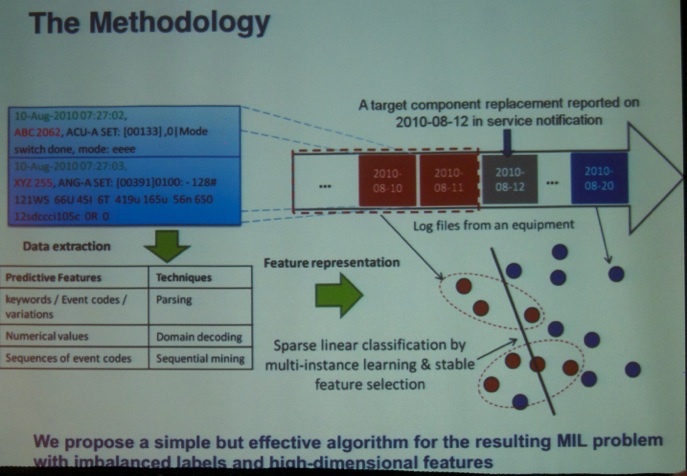



Next, the paper titled “Unveiling Clusters of Events for Alert and Incident Management in Large-Scale Enterprise IT” was presented by Derek Lin (@Pivotal, Pivotal Software, Inc.), Rashmi Raghu (Pivotal Software, Inc.), Vivek Ramamurthy (Pivotal Software), Jin Yu (Pivotal Software), Regunathan Radhakrishnan (Pivotal Software), Joseph Fernandez (Visa).


Next, the paper titled “Scalable Near Real-Time Failure Localization of Data Center Networks” was presented by Herodotos Herodotou (Microsoft Research), Bolin Ding (Microsoft Research), Shobana Balakrishnan (Microsoft Research), Geoff Outhred (Microsoft), Percy Fitter (Microsoft).


The next presentation was titled “Correlating Events with Time Series for Incident Diagnosis” by
Chen LUO (Jilin University), Jian-Guang LOU (Microsoft Research), Qingwei LIN (Microsoft Research), Qiang FU (Microsoft Research), Rui DING (Microsoft Research), Dongmei ZHANG (Microsoft Research), Zhe WANG (Jilin University).



Finally, the last talk of the Monitoring and Maintenance Session was titled “Large Scale Predictive Modeling for Micro-Simulation of 3G Air Interface Load” by Dejan Radosavljevik (Leiden University), Peter van der Putten (Leiden University).

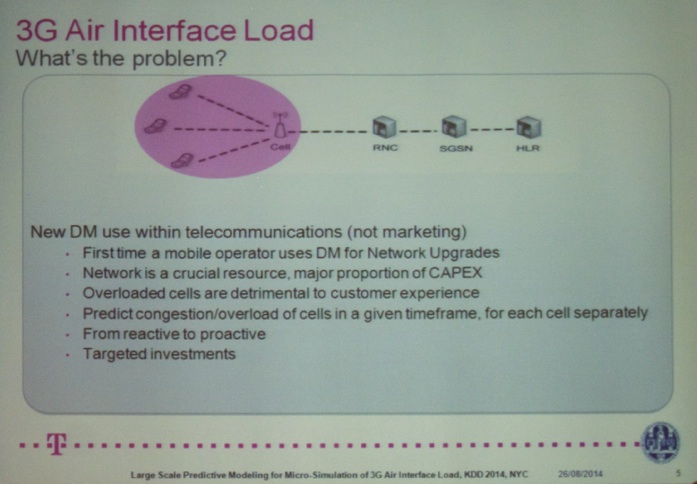
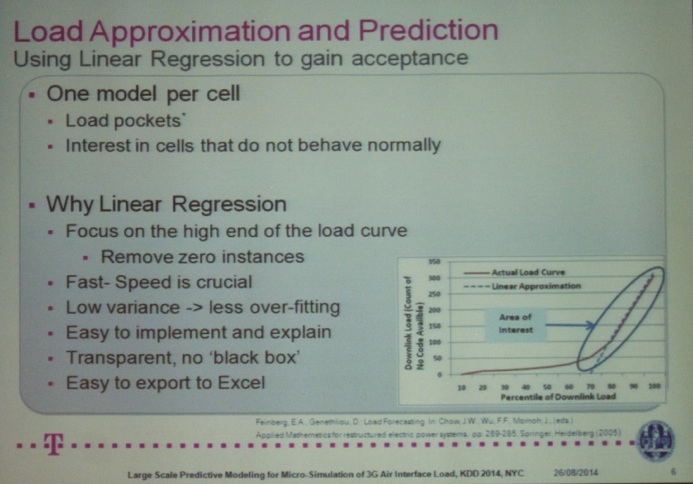
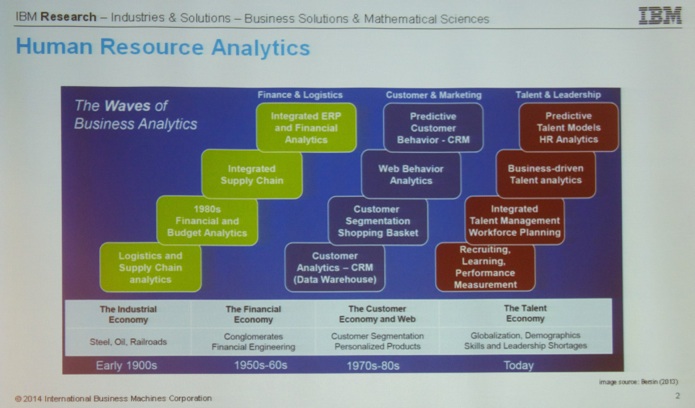
After the coffee break, I attended the Workforce Analytics and Personalization Session. HR Analytics is definitely a hot topic lately. We already completed several projects in this field (e.g. click here for the Master of Science in Marketing Analysis project on this topic). Hence, I was interested to see what others are doing in this field.
The first talk was titled “Predicting Employee Expertise for Talent Management in the Enterprise” by
Kush R Varshney (IBM Thomas J. Watson Research Center) et al.





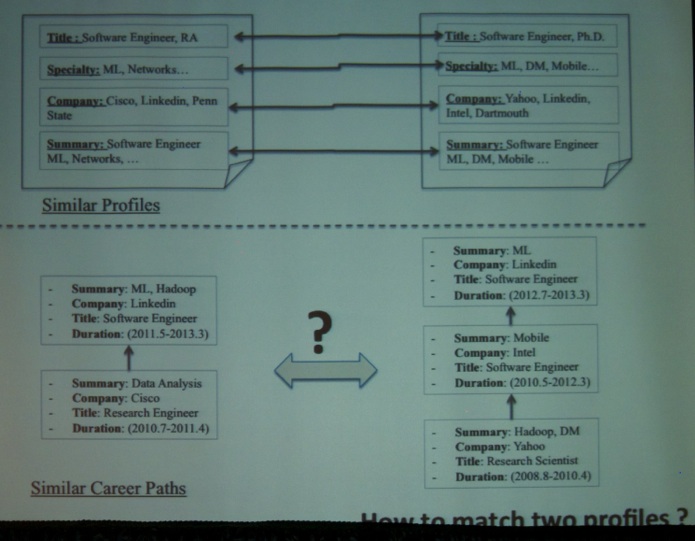
The next talk was titled “Modeling Professional Similarity by Mining Professional Career Trajectories” by Ye Xu (Dartmouth College), Zang Li (LinkedIn Corporation), Abhishek Gupta (LinkedIn Corporation), Ahmet Bugdayci (LinkedIn Corporation), Anmol Bhasin (LinkedIn Corporation).



The next paper was titled “A System to Grade Computer Programming Skills using Machine Learning” by Shashank Srikant (@myamcat, Aspiring Minds), Varun Aggarwal (Aspiring Minds).




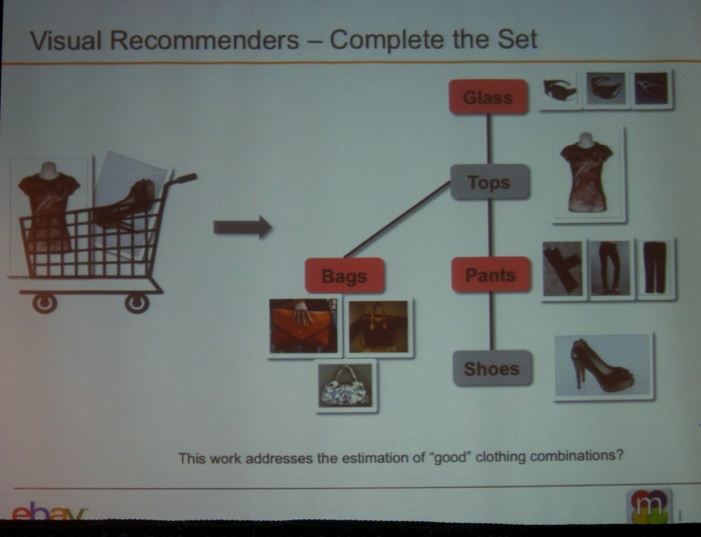
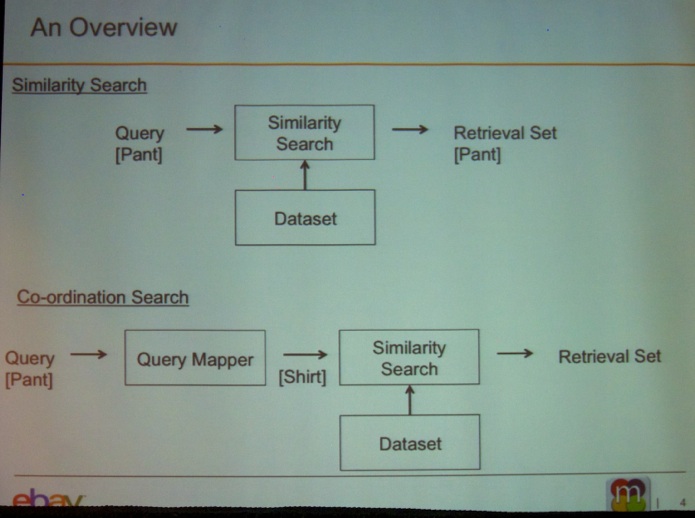
The next talk was titled “Large Scale Visual Recommendations From Street Fashion Images” by Vignesh Jagadeesh (eBay Research Labs), Robinson Piramuthu (eBay Research Labs), Anurag Bhardwaj (eBay Research Labs), Wei Di (eBay Research Labs), Neel Sundaresan (eBay Research).



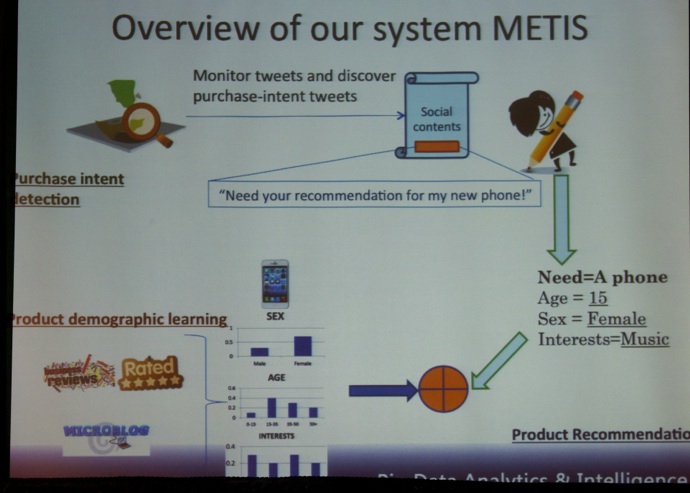
Next, the paper titled “We Know What You Want to Buy: A Demographic-based System for Product Recommendation On Microblogs” was presented by Xin Wayne Zhao (Renmin University of China, see picture below) et al.


That evening was the KDD Dinner at Pier 60 with a nice view on the Hudson, the Freedom Tower and New Jersey. Thank you Bloomberg for sponsoring the dinner.



The final day of the conference started again with KDD Madness - a spotlight session with a one-slide summary per paper.


Next up was the keynote session by Dr. Eric Schadt (Director of the Icahn Institute for Genomics and Multiscale Biology, see picture below). He started off his talk on how to analyze medical data for improved diagnosis and treatment. Moreover, he discussed a potentially important discovery, where his team found a kind of "magic module" network of genes linked to inflammation that is involved in many diseases (e.g. Alzheimer).


Next, I attended the Novel Applications Session. The first talk in this session was titled “Grouping Students in Educational Settings” by Rakesh Agrawal (Microsoft Research), Behzad Golshan (Boston University, see picture below), Evimaria Terzi (Boston University).



The next talk was titled “Inferring Gas Consumption and Pollution Emission of Vehicles throughout a City” by Jingbo Shang (Shanghai Jiao Tong University), Yu Zheng (Microsoft Research, see picture below), Wenzhu Tong (Microsoft Research), Eric Chang (Microsoft Research), Yong Yu (Shanghai Jiao Tong University).



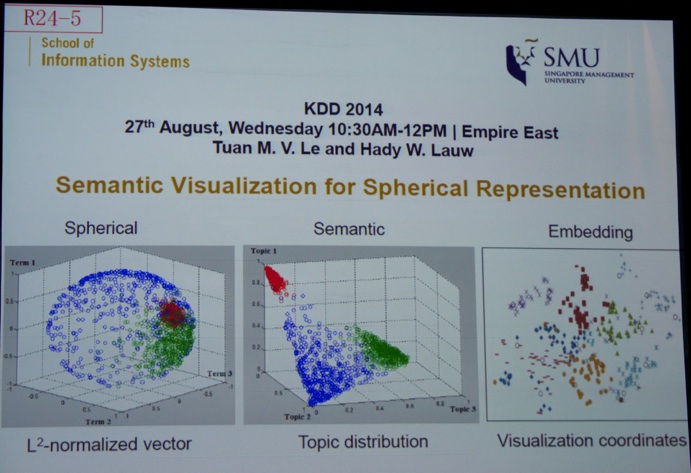
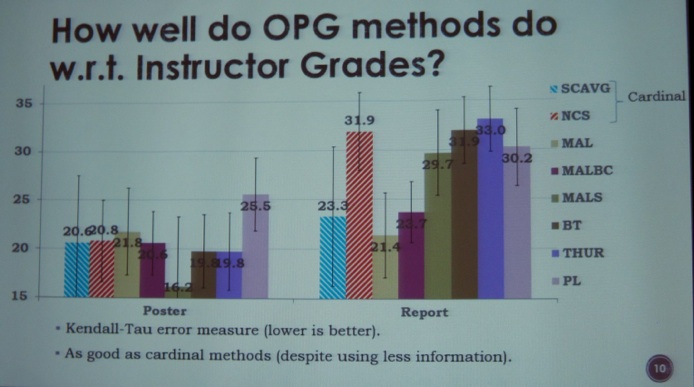
The next presentation was titled “Methods for Ordinal Peer Grading” by Karthik Raman (Cornell University, see picture below), Thorsten Joachims (Cornell University). The topic of ordinal peer grading is particularly important in the age of MOOCs. I also liked the evolution that more authors also make available their #opensource code (in this case: http://www.peergrading.org ). See this link for more links to source code (thanks @williampli).




The next talk was titled “Exploiting Geographic Dependencies for Real Estate Appraisal” by Yanjie Fu (Rutgers University), Hui Xiong (Rutgers University), Yong Ge (University of North Carolina at Charlotte), Zijun Yao (Rutgers University), Yu Zheng (Microsoft Research Asia), Zhi-Hua Zhou (Nanjing University).



The final talk of this session was titled “Towards Scalable Critical Alert Mining” by Bo Zong (University of California, Santa Barbara), Yinghui Wu (University of California, Santa Barbara), Jie Song, LogicMonitor; Ambuj K. Singh, University of California, Santa Barbara; Hasan Cam, Army Research Lab; Jiawei Han, University of Illinois at Urbana-Champaign; Xifeng Yan, University of California, Santa Barbara;




After lunch, I attended the panel discussion on the topic “Does Social Good Justify Risking Personal Privacy?”. They again used the online tool to rank questions from the audience.


Finally, the closing keynote was held by Prof. Dr. Sendhil Mullainathan (@m_sendhil, Professor of Economics at Harvard University). He discussed topics such as correlation versus causation, randomized experiments, ...




Prof. Dr. Chris Clifton (Purdue University assigned to the NSF, see picture on the right) also shared his view on the matter.
Finally, the conference concluded with an invitation for next year’s edition in ... Sydney, Australia. See you all down under... stay tuned at @kdd_news.
