Oracle Big Data Forum in Belgium

Prof. Jean-Jacques De Clercq attended an Oracle Big Data Forum event in Belgium on June 27, 2013. Below, you find his summary of the event:
Jan Ronsse (Senior Sales Director at Oracle Belgium, see picture above) welcomes the attendees. Mr. Xavier Verhaeghe (VP Tech & Big Data Benelux, see picture below) kicks of the event with an introductory presentation titled “Big Data: Accelerating in the Real World”. Organizations will have to handle data at extreme scale, sometimes even in real time using existing or new software tools because of e.g. the growing use of internet, mobile data explosion with added location content. Big Data is not only used for sentiment analysis in social media but in all layers of business, medical care, sensor data analysis, product design, context based engagement, event processing, financial & fraud prevention. Most popular projects at the moment are for mobile strategy, for better customer experience, for churn prevention, and for data warehousing. To implement this we will need more cost efficient ways for analyzing data, integration with existing databases so we can reuse the data for other purposes, simplifying the software platform so end users can work independently and define their own needs. Currently, Cloudera is the biggest player with its commercial implementation of the Hadoop open source. Oracle has tried to unite both worlds of SQL and No-SQL by introducing the new Oracle Big Data Appliance. This appliance will be responsible for the extraction (cf. ETL technology) of the data (web crawling) from internet and social media, streaming this data through the Hadoop connector to the Cloudera environment and finally analyzing the data with the Exadata appliance to generate the required reports.
Saturday 6 July 2013

Oracle projects that have been run on this new appliance: media customer profiling, automotive sentiment analysis (sensors reporting location problems), game analysis, energy trading (buying or selling energy surplus), real-time mass event processing, quality analysis & design support, fraud prevention, real-time personalization (collect customer profiles on social media), engineering big data platform, clinical trials on Genomics, people career matching, patient sensoring, drilling exploration, market optimization and finally student performance analysis. The latter analysis is done in the Turkish educational system to measure the impact of teacher training on the progress of students as an extra added value for education.
To enable end users to learn more about big data Oracle is organizing 2 workshops: one on Big Data Discovery (value for customer) and one about Big Data architecture (software techniques + cost impact).
Next, Stephen Line (Account Executive at Cloudera) takes the stage:

Cloudera was founded in 2008, consisting mainly of people from Yahoo and Facebook.
Why is Big Data becoming a success story: Two recent surveys give a clear indication. First the Tice survey about salary analysis calculated the impact of certain skills on the salary and concluded that the three biggest risers are Big Data, Hadoop and NoSQL. A second survey of Gartner concluded that deploying Big Data capabilities gives a company a 20% advantage over the competition.

This year, Cloudera introduced three new products: Impala (interactive queries in real-time), Cloudera Navigator (understand what happens with data in Hadoop), Tech marriage between Oracle and Cloudera with OBDA (Oracle Big Data Appliance which consists of CDH + CM + Hbase).

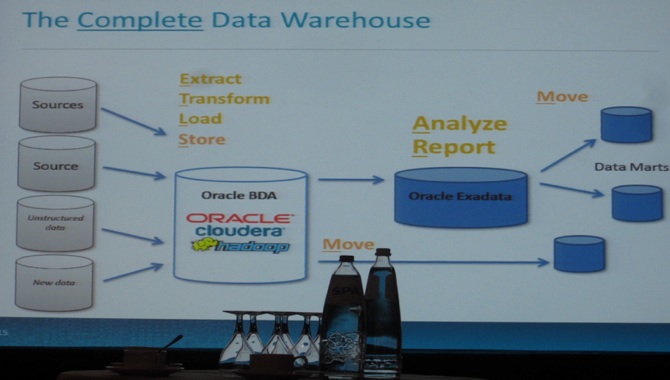
The conventional BI-DW architecture consisted of the following steps: Datasource ETL (Extract-Transform-Load) DW (Analyze + Report) Data Marts (views of data depending of user profile in that department). The data deluge causes problems because data-warehousing performance is considerably decreasing under this data tsunami. The solution to this problem is the Goldmine strategy. Instead of extracting the mud and filtering out the gold you extract the gold directly from the mud (analytic process instead of transform). This is obtained thanks to the Map/Reduce paradigm of Hadoop. What are the fundamentals of Hadoop: (1) COMPUTE: fault-tolerant (all data is replicated three times simulating a software RAID use BOD’s=bunch of disks instead of RAID-drives), processing is distributed or parallel, schema-on-read. (2) STORE: self-healing, no transformation high bandwidth, less duplication and movement of data, more different kinds of data possible. Opportunities by using this technique: no batch constraints, analytic vs transform, processing vs data movement, historical & immediate data (RT processing possible), new types of data, dynamic modeling.
New BI-DW architecture:

Now we “ETL + store” data directly, and then we “Analyze + Report” on it before moving the views to the Data Marts. The software stream consists of: CDH (storage + compute) + CM (Cloudera Manager for any type of data) + Support tools (Economics of Data Management).
Use Cases: Telco generates 0,5PB data per day all data is analyzed at once instead of a 10% sampling rate which gives you a more exact picture. Travel company has 450Tb of data on a 2 year basis. By analyzing the clickstream data in real-time it can optimize Google AdWord right away.
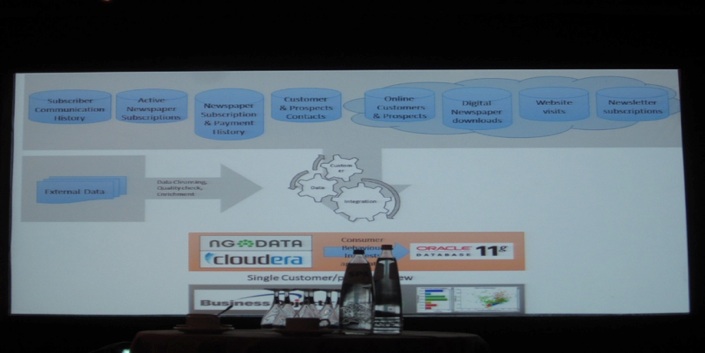
Luc Verbist (CIO at De Persgroep) starts his talk by saying that the “De Persgroep” media group consists of: 4% Radio (Q-Music), 14% TV (VTM, AT5, Vitaya, Jim), 4% Digital (De Morgen, iPad apps), 8% Mobile Telco (JIM Mobile, Paratel), 70% Publishers of different Newspapers (De Morgen, Vacature etc).
Its marketing strategy was purely B2C or mass marketing of big groups, no detail of customers (readers, consumers). To get more precise customer insights one needs additional behavioral and location data. All these data exist for the moment but is not being used. Marketing data are being logged as well including sales of cooking books (Piet Huysentruit 130K books), James Bond movies, DVD-players. However customer reactions (tweets) are not logged.
Data storage includes 1.2 million customers, 11 million prospects, 140 million pageviews, 110 million tweets requires a Big Data project being set up because all systems are distributed and not integrated (CRM for Printing and Digital are separated).
Market Survey of Big Data systems: compared all possible Big Data solutions and Oracle proved to be the cheapest solution with their new Oracle BDA proposal. An additional advantage was that everything was installed and ready to go without intervention of own IT-people so faster time to market. Starting with 1/3 SUN rack makes it easily scalable. Use of LILY (NG-Data) for analytics.

Objectives of the Big Data project:
-Overview of frequency of reading habits who and how many read an article.
-Store IP-address (easy in The Netherlands but more complicated in Belgium) of drop by candidate customers on the website to collect leads and obtain additional subscribers.
-Marketing of readers: upsell & cross-sales, reader recruitment, reduce churn, handle complaints about bad delivery (mail voucher at renewal time as compensation).
-Advertising: more targeted campaigns (advertise depending of customer profile), more personalized ads, multi-channel campaign.
-Editorial case: score for each article channel (newspapers mostly read at 11, tablets at noon), personalize news content (what do you read), adapt news content during the day.
-Privacy legislation: process data fairly and lawfully, more accurate data (no sampling) with consent of customer, poll acquisition with non-intrusive questions.
Pesonnel involved: 3 IT people + 1,5 outsourced people from NG-data + 5 statistical experts in marketing department. Last mentioned employees are very hard to find (cf. ‘Master of Marketing Analysis’ Ghent University’ or ‘Master of Science in Business Engineering: Marketing Engineering’)
Problems: deduplication and identification of customers is a very though job and will involve experts in data science, predictable savings is difficult, handling massive volumes has to be learned by marketing staff.

Next, Frank Hamerlinck (COO of NG Data, see picture below) takes the stage. NG Data was founded with ING + Venture Capital in 2009. Latest release for LILY 2.2 (Customer Intelligence for Banking, Publishing, Telco & Retail sectors). HQ in Ghent and subsidiaries in San Francisco & NY City. LILY Enterprise: channeled info combined with location data and Datawarehouse data profiling of customers more targeted marketing and advertising.
Software stream: Hbase + ETL (Pentaho) + Hive + Impala + Business Objects (reporting) + SAS + Dashboards + Business Rules + Machine Learning Algorithms (calculate preference in real time) + Knowledge Based Algorithms. Customer explorer of Lily enables to define the preference for a certain product by using gender, type of subscription, clickstream info.

Solutions handed by Lily: single customer view, product recommendations (merge credit card with location data), Twitter Sentiment analysis Lily quadruples marketing efficiency ! Customer experience = Sum of goods/suppliers/services.

These are some examples:
Obama: analyzed voters with Big Data filtering on swing voters.
Banking: cross-sell, restore customer trust (giving them a sense of intimacy), customer churning (JP Morgan, Citibank, Bank of America).
Movies (Netflix): viewer info define most popular actors, programs etc.
Disney: services OLTP ODS RFID wristband customer intimacy.
IDC: unstructured (video, rich media), semi-structured (Blogs), structured database data.
Personalization: Guardian, Trinity Mirror etc.
Next, Christophe Moortgat (CEO at Uptime-Cronos) talks about an approach to deal with emerging technologies.
In sum, it was an interesting Oracle Big Data Forum event with examples of what Big Data has to offer...

