GfKl 2012 Classification Conference in Hildesheim (Germany)

The 36th Annual Conference of the German Classification Society (GfKl) was held in beautiful Hildesheim (Germany, see picture above). The actual conference venue was just outside of town in Domäne Marienburg (see picture to the right). This year, it was a joint event with the Polish Classification Society. Scientific Program Committee chair was Prof. Dr. Myra Spiliopoulou (University of Magdeburg). Local organizers were Prof. Dr. Lars Schmidt-Thieme & Dr. Ruth Janning (University of Hildesheim, Germany). After registration (see below - left) Prof. Dr. Wolfgang-Uwe Friedrich (President of the University of Hildesheim, see below - right) opened the event.
Friday 3 August 2012


Next, Prof. Dr. Claus Weihs (President of GfKl, see below) said a few words.


Next, two award-winning papers of last year’s conference were invited to give a summary talk about their research.

After a welcome by the chair of the scientific program committee Prof. Dr. Myra Spiliopoulou (see picture below - left), and the local organizer Prof. Dr. Lars Schmidt-Thieme (see picture below - right), it was time for the first keynote talk by Prof. Dr. Wolfgang Gaul (see picture below).


The break-out sessions were up next. I attended the “Data Analysis and Classification in Marketing”. First up was the talk by Prof. Dr. Daniel Baier with his paper “Spatial Modeling of Dependencies Between Population, Education, and Economic Growth” (co-authors: Wolfgang Polasek and Dr. Alexandra Rese).



Dr. Alexandra Rese presented the paper “Rasch Models for Analyzing Role Models in Inter-Organisational Innovation Processes” (co-authors: Hans-Georg Gemünden and Daniel Baier).

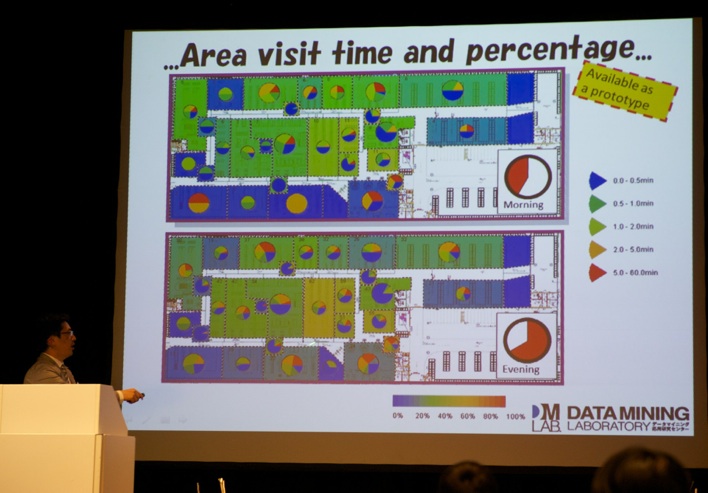
The afternoon session started with a keynote by Prof. Dr. Katsutoshi Yada (Kansai University, Japan).

Prof. Dr. Katsutoshi Yada provided an interesting overview of methodologies used to analyze shopping paths.

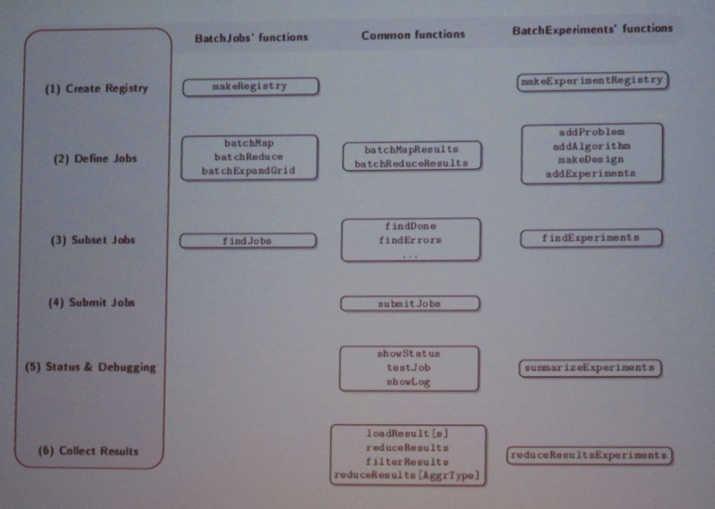
Next, I attended the session in the “Statistics and Data Analysis: Classification 1” section. First, Dr. Bernd Bischl (co-authors Julia Schiffner and Claus Weihs) presented the paper “Benchmarking classification algorithms on high-performance computing clusters”. Given my particular interest in the area, this was one of my favorite talks of this GfKl conference. They published two R packages (BatchJobs and BatchExperiments) to facilitate carrying out large-scale comparison studies. They demonstrated the usefulness of their approach to a large-scale experiment assessing the impact of outlier removal on classification performance.
Next, Keiji Takai presented an interesting paper (co-authored with Kenichi Hayashi): “Effects of Labeling Mechanisms on Classification Error in Linear Discriminant Analysis”.
After the break, I attended the “Statistics and Data Analysis: Statistics in Economics” section. This session started off with a talk by Justyna Brzezinska (see picture below) titled “Visual models for categorical data in economic research”. She talked about the vcd and vcdExtra packages in R providing nice visualizations for contingency tables.

Next, Christian Bravo (see picture below) presented the paper (co-authored with Miguel Biron) “Empirically Measuring the Effect of Violating the Independence Assumption in Behavioral Scoring”.


Finally, Dr. Marcin Pelka presented the paper (co-authored with Bartlomiej Jefmanski) “Fuzzy Composite Index for Customer Satisfaction Evaluation: An Application for Public Sector Services”.

Next, we attended the guided city tour organized by the conference. This led us to some beautiful spots in the nice town of Hildesheim.

The city tour ended in the City Hall of Hildesheim (see picture below), where we were greeted by the mayor (see picture below), followed by a reception.






Thursday morning started with a keynote talk by Prof. Dr. Joao Gama (University of Porto) titled “Data Stream Mining for Ubiquitous Environments”. He explained an interesting application for very-short-term forecasting in photovoltaic systems.




Next, yours truly (@dirkvandenpoel) attended the paper by Sergej Potapov, Asma Gul, Werner Adler and Berthold Lausen: “Decision tree ensembles with different split criteria”. It discussed Prof. Dr. Berthold Lausen (University of Essex, UK)’s p-value adjusted classification trees. They implemented their adjustment by association test as split criterion in an R Package called party.

Next, we decided to attend Ruben Hillewaere (VUB, Belgium, see picture below)’s talk - the only other Belgian besides Michel & myself at the conference - about his PhD research using alignment methods for folk tune classification. It’s interesting to observe so many applications of alignment methods in very diverse scientific fields.

After lunch, we attended Prof. Dr. Michele Sebag (see picture below)’s talk on “Autonomous Robotics: Defining Instincts and Learning Systems of Values”. She gave a nice overview of theory in reinforcement learning as well as some applications in robotics.

Then it was time for a small promo for next year’s GfKl 2013 conference. Local organizer Prof. Dr. Sabine Krolak-Schwerdt said a few words about the unique conference venue... .

Then, after the general assembly of GfKl members (Mitgliederversammlung, see picture below), it was time for the conference dinner.

On Friday morning, I had the honor of giving my plenary talk (see picture below) titled “On the value of incorporating sequential information into predictive analytics classification models for analytical CRM”. My talk was a summary of the following papers with two former PhD students (Dr. Anita Prinzie & Vera Miguéis):
MIGUEIS V.L., VAN DEN POEL D., CAMANHO A.S., CUNHA J. F. (2012a): Predicting partial customer churn: On the value of the purchasing sequence, ESWA, 39 (12), 11250-11256.
MIGUEIS V.L., VAN DEN POEL D., CAMANHO A.S., CUNHA J. F. (2012b), Predicting partial customer churn using Markov for Discrimination for modeling first purchase sequences. ADAC, forthcoming.
PRINZIE A. and VAN DEN POEL D. (2006a): Incorporating sequential information into traditional classication models by using an element/position-sensitive SAM. Decision Support Systems, 42 (2), 508-526.
PRINZIE A. and VAN DEN POEL D. (2006b): Investigating Purchasing Patterns for Financial Services using Markov, MTD and MTDg Models. European Journal of Operational Research, 170 (3), 710-734.
PRINZIE A. and VAN DEN POEL D. (2007): Predicting home-appliance acquisition sequences: Markov/MTD/MTDg and survival analysis for modeling sequential information in NPTB models. Decision Support Systems, 44 (1), 28-45.


Next, I had to chair the “Data Analysis and Classification in Marketing” session. So, I was unable to attend Dr. Dirk Thorleuchter’s talk on “Espionage Risk Assessment for Security of Defense based Research and Technology”.
In my session, the first presenter was Pascal Kottemann (see picture below, co-authors: Martin Meissner and Prof. Dr. Reinhold Decker, Bielefeld University): “Measuring Consumers’ Brand Associations in Online Market Research”

Next, Michel Ballings (see picture below - left) presented our paper “The Dangers of using Intention as a Surrogate for Retention in Brand Positioning Decision Support Systems”, followed by Friederike Paetz (see picture below - right; co-author Prof. Dr. Winfried J. Steiner) who presented the paper titled “Finite Mixture MNP vs. Finite Mixture IP Models: An Empirical Study”.


Next, I attended the “Ensemble methods in clustering and classification” session. First, Andreas Ziegler (co-author: Jochen Kruppa) presented the paper: “Probability Machines: Estimating individual
probabilities using machine learning methods”.


Next, Silke Janitza (co-authored with Prof. Dr. Anne-Laure Boulesteix) presented “An AUC-based Permutation Variable Importance Measure for Random Forests”.

Next, I attended the presentation by Werner Adler (co-authors: Zardad Khan, Sergej Potapov and Prof. Dr. Berthold Lausen): “Diversity Based Weighting to Improve the Performance of Classifier Ensembles”.


The closing plenary was given by Prof. Dr. Shai Ben-David (University of Waterloo, Canada): “Universal Learning vs. No Free Lunch results - can there be learners that do not require task-specific knowledge?”.

A big thank you to the organizers (see picture below) for putting together a scientifically-stimulating conference! See you all in Luxemburg for the next edition of the GfKl (July 10-12, 2013), branded as the “European Conference on Data Analysis”. It’s a joint conference with the French Classification Society.


