In-Database Analytics with Oracle Data Mining

This year is a special year for the class ‘Marketing Information Systems/Database Marketing’ (part of the Marketing Engineering curriculum as well as Master of Science in Marketing Analysis curriculum). To date, the focus has been on extracting information from company databases with the aim of building modular and reusable procedures and functions (using Oracle SQL and PL/SQL) for descriptive/operational marketing applications. Although descriptive applications are very important, they are by far not as exciting as predictive applications. That’s why we decided to take the class one step further with Oracle Data Mining (ODM). Michel Ballings was in charge of this part as a TA (see picture above). By entering the analytical arena, which in the ME/MMA programs has been dominated by SAS and Matlab, we open up a whole new array of possibilities, namely in-database analytics.
The following funny video explains the advantages of ODM over SAS and Matlab:
Monday 19 December 2011

In sum, data mining within the Oracle 11g database offers the following advantages:
•No Data Movement. Some data mining products require that the data be exported from a corporate database and converted to a specialized format for mining. With Oracle Data Mining, no data movement or conversion is needed. This makes the entire mining process less complex, time-consuming, and error-prone.
•Security. Your data is protected by the extensive security mechanisms of Oracle Database. Moreover, specific database privileges can be set for different data mining activities. For example, only users with the appropriate privileges can score (apply) mining models.
•Ease of Data Refresh. Mining processes within Oracle Database have ready access to refreshed data. Oracle Data Mining can easily deliver mining results based on current data, thereby maximizing its timeliness and relevance.
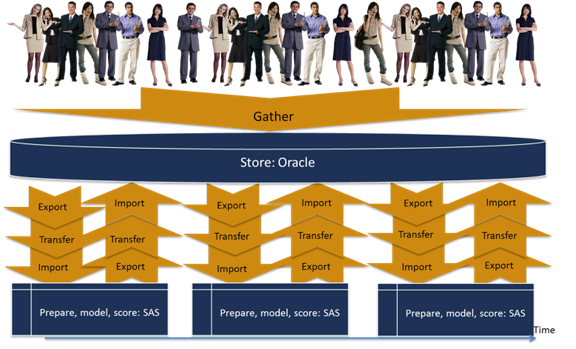
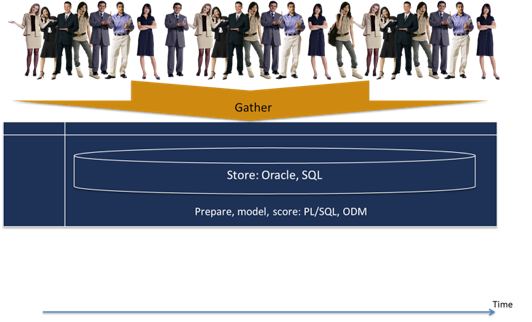
The two figures below indicate the aforementioned points:
Below, you see a Figure showing a setting NOT using in-database analytics: From customer behavior to analysis.
 |
The Figure below shows the setting USING in-database analytics: From customer behavior to analysis.
Next to new content (ODM), we also innovated in the teaching form. We are always aiming at improving the course material and that’s why Michel Ballings (assistant for the PL/SQL and ODM part of the course) has put in a lot of work to design the ODM material for the course in tutorial form, making it easier for the students to digest the material. The tutorial explains how to program a model building and customer scoring application, one step at a time. As a guide, CRISP-DM (CRoss-Industry Standard Process for Data Mining) is followed: Business Understanding, Data Understanding, Data Preparation, Data Model, Model Evaluation and Model Deployment. To embed all the steps into one procedure, we focused strongly on dynamic SQL.
Here’s a small example of a call to the CREATE_MODEL function in an anonymous block.
BEGIN
dbms_data_mining.CREATE_MODEL(
model_name=>'glm_model',
mining_function=>dbms_data_mining.classification,
data_table_name=>'tutorial_train',
case_id_column_name=>'customer',
target_column_name=>'bought_product',
settings_table_name=>'glmsettings');
END;
/
To fuel the students’ interest, we asked them to compete in our own Oracle Data Mining Cup in teams of three. They had to write a predictive model-building application, embedded in a single procedure and give a presentation about their best three predictors. The goal was to build the best retention model (in terms of AUC). The winning team’s strategy was to compute many variables (dynamically) including a lot of interactions between them. They also found that certain employees had a negative influence on retention.

In sum, we received very positive feedback about the new part of the course, which convinces us even more that we have to continue to walk the path of in-database analytics with Oracle. Plans for further integration of ODM in next year’s class are already being made.

Finally, below, the winning team is shown! Congratulations to all!







