IEEE Data Mining Conference: ICDM 2011 in Vancouver, Canada

551 researchers from 39 countries came to Vancouver, BC for the annual ICDM IEEE data mining conference. The main topics of this conference were: data mining algorithms (of course), open source software for big data, text (sentiment) analysis, exascale supercomputing, privacy-preserving data mining, recommender systems, social media.
Tuesday 13 December 2011

Yours truly decided to attend the “Sentiment Analysis in Practice” tutorial on the first day presented by
Yongzheng (Tiger) Zhang from eBay Research Labs (see picture below). He gave an excellent overview of the field, the approaches, the algorthms to use, ... . Document-level, sentense-level, and attribute-level sentiment analysis were discussed... and much more.

Important indices such as the Pointwise Mutual Information (PMI) measure were introduced. SentiWordNet, OpenNLP, ... were mentioned. In sum, a great tutorial. Finally, many key sentiment analysis applications were discussed:
Opinion Summarization, Opinion Search & Retrieval, Opinion Spam & Opinion Quality, Opinion Ranking.


The reception event at the evening of the first day was great for networking (the food was not the reason for attending ;-). The next morning started with a keynote by Professor Lee Giles (see picture below), which addressed the topic of data mining of large information sources e.g. CiteSeerX. They developed SeerSuite, an open-source search engine to make big data easily accessible.
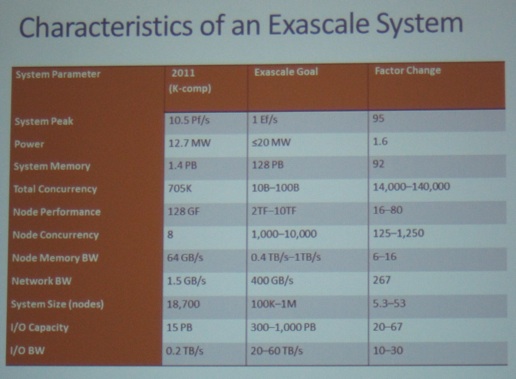
Next, I visited a session on the challenges in developing data mining solutions that can run on exascale-class machines. Dr. George Karypis started off with a nice comparison (see slide below): where we are today (K-computer) vs the goal (1 exascale computer). See slide below. In particular, notice the last column, which tells you how many times our goal is from today’s situation.

"The power issue for an Exascale system is well-known" says Dr. Mootaz Elnozahy (Master Inventor at IBM Research, see picture to the right). Moreover, he emphasizes that reliability will become a major issue in Exascale systems. Current supercomputers are in the range of 20 MTBF (mean time between failure) days, hence Exascale systems would fail (on average) several times a day, which is not acceptable. Programmers can live with today’s setting, but not with the estimated reliability of exascale systems.
Next, Professor Barbara Chapman (University of Houston) took the stage (see picture below). One of the most interesting things she talked about was the OpenACC(elerator) project: OpenMP across heterogeneous cores.

Dr. Chandrika Kamath (Lawrence Livermore National Lab, see picture to the left) talked about opportunities provided by Exascale systems: Uncertainty quantification (to allow for more detailed sensitivity analysis), real-time analysis of streaming data, reasoning in the presence of uncertainty.


Professor Srinivasan Parthasarathy talked about the many challenges that large-scale data analytics pose: latency (see picture below), bandwidth, adaptability, heterogeneity, green & productivity.
Dr. Cynthia Dwork (Scientist at Microsoft Research) gave a keynote talk about privacy breaches. Moreover, she reviewed definitions of privacy preservation. Then the concept of "Differential privacy" was introduced. It describes a promise, made by a data curator to a data subject: you will not be affected, adversely or otherwise, by allowing your data to be used in any study, no matter what other studies, data sets, or information from other sources is available.

The conference also included an excursion to the Capilano bridge. So it was time to board the busses toward this tourist attraction. Immediately after the visit, we had the conference dinner with the award ceremony (see pictures below).


Subsequently, I attended the tutorial titled “Mining Sets of Patterns: Next Generation Pattern Mining” (see picture below). In general, all tutorials were very well attended.

During the community meeting lunch Prof. Dr. Shusaku Tsumoto presented interesting trends about the ICDM conference over the past years.

Next, I attended Toon Calders’ presentation (see pictures below) titled “Handling Conditional Discrimination” (co-authors: Indre Zliobaite, Faisal Kamiran). They study how to train classifiers on historical data, which may contain discrimination, so that they are discrimination free with respect to a given sensitive attribute; e.g., gender. The authors decompose discrimination into an explainable part, and and unexplainable part. Great talk, great paper!
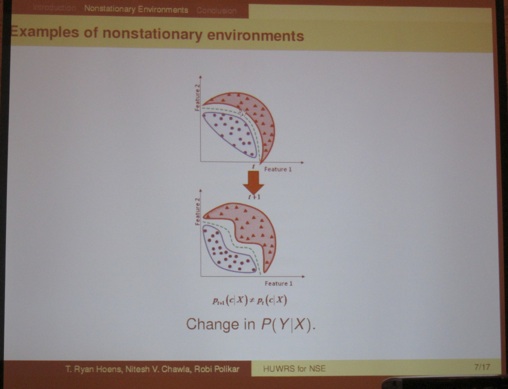
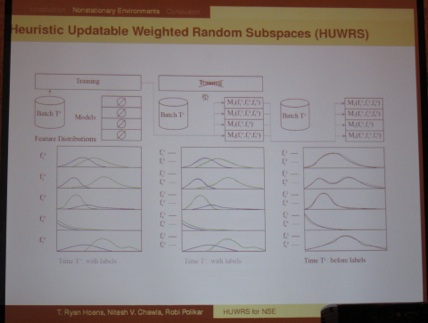
From the same session, I would also like to highlight the presentation: “Heuristic Updatable Weighted Random Subspaces for Nonstationary Environments” (Thomas “Ryan” Hoens, Robi Polikar, and Nitesh Chawla). In non-stationary environments data arrives incrementally. The authors introduce a new technique based on the Random Subspace Method that detects drift in individual features via the use of Hellinger distance, a distributional divergence metric: Heuristic Updatable Weighted Random Subspaces (HUWRS).
Next, the best paper award winner presented the paper “Personalized Travel Package Recommendation” (authors: Qi Liu, Yong Ge, Zhongmou Li, EnHong Chen, and Hui Xiong). The room was packed with listeners (picture below).








I do realize that I am doing injustice to all the other interesting presentation, but that’s the selection I made. See you next year in Brussels for another exciting ICDM conference.

